




Discover, analyze and remediate sensitive data anywhere
Personal data where it shouldn't be?
Our fast and accurate AI software will find and fix it.


Control data risk with powerful AI

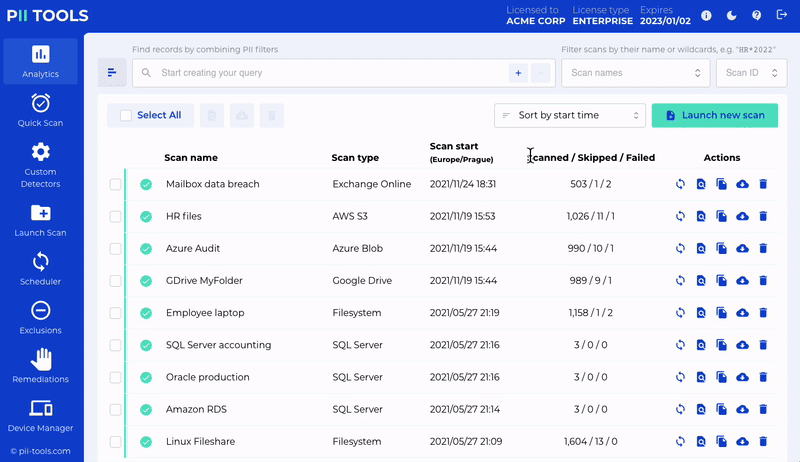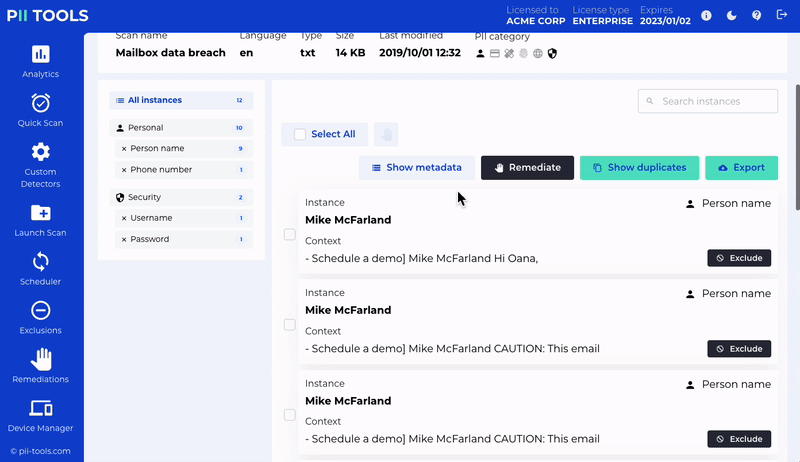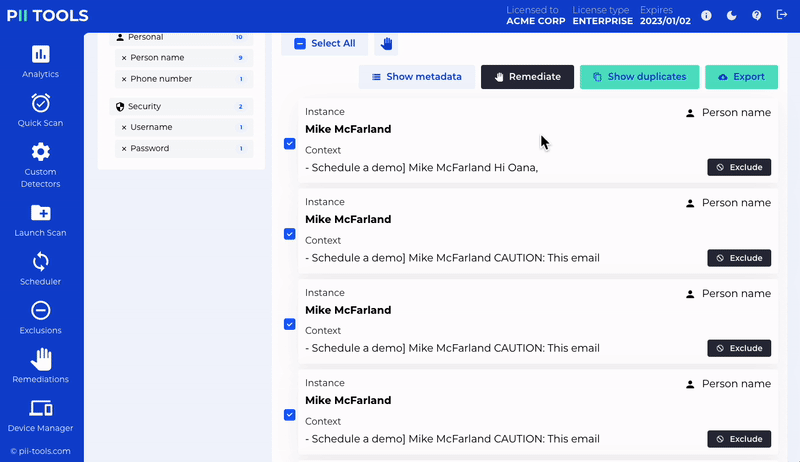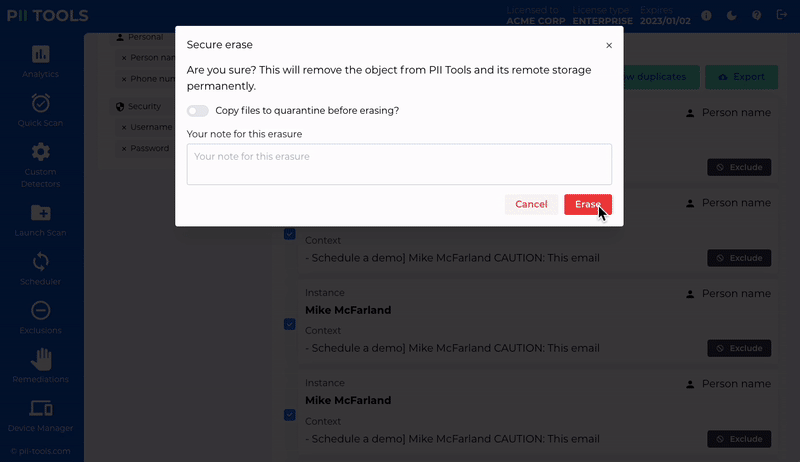
Discover
Scan for all personal or sensitive information securely. No data leaves your network.

Report
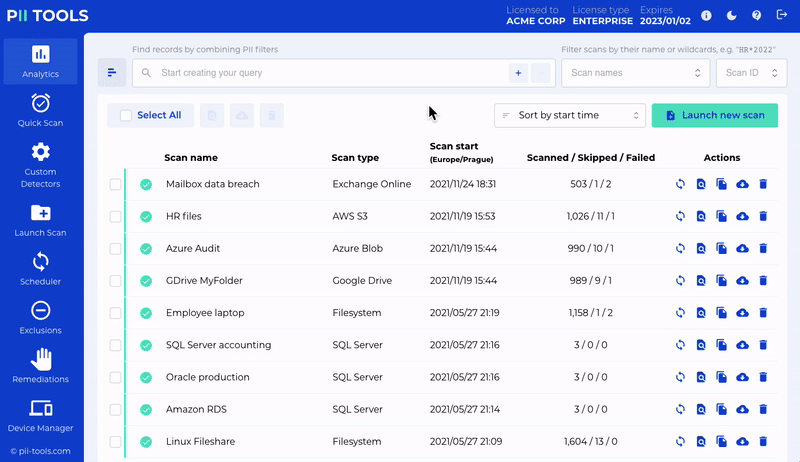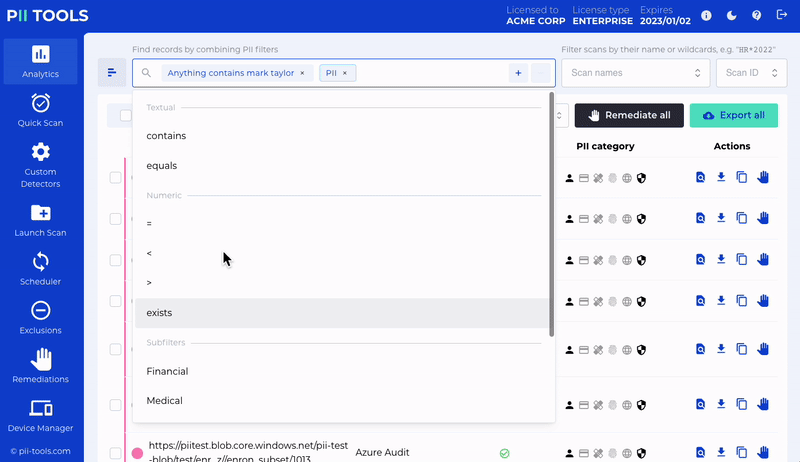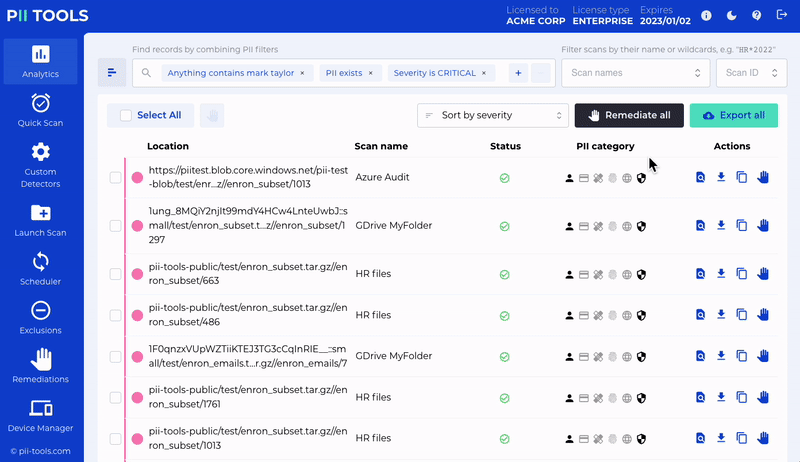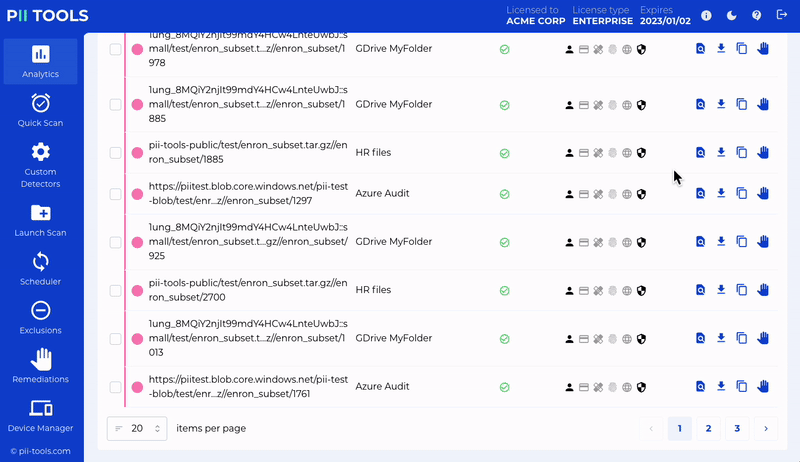
Analyze and review discovered data based on who is affected, where and how.

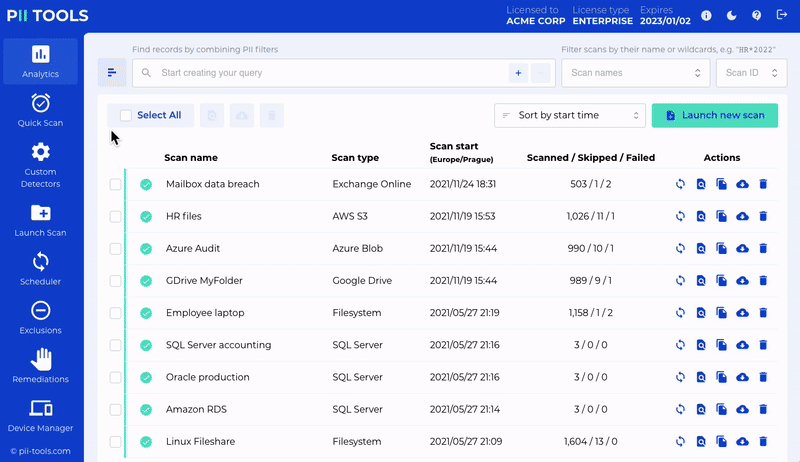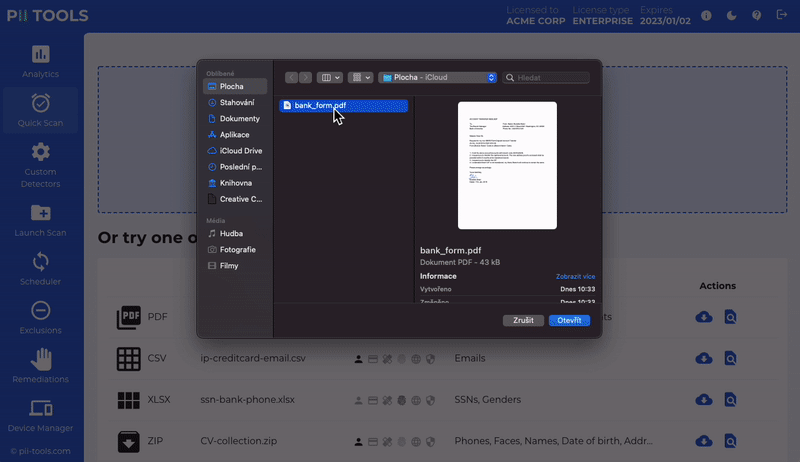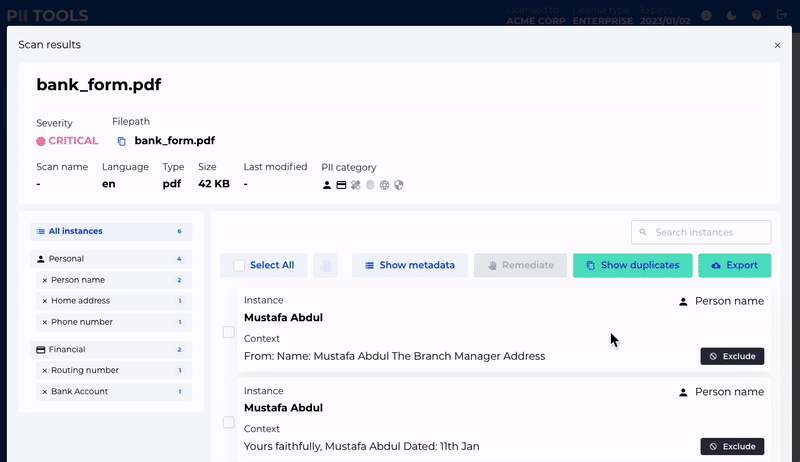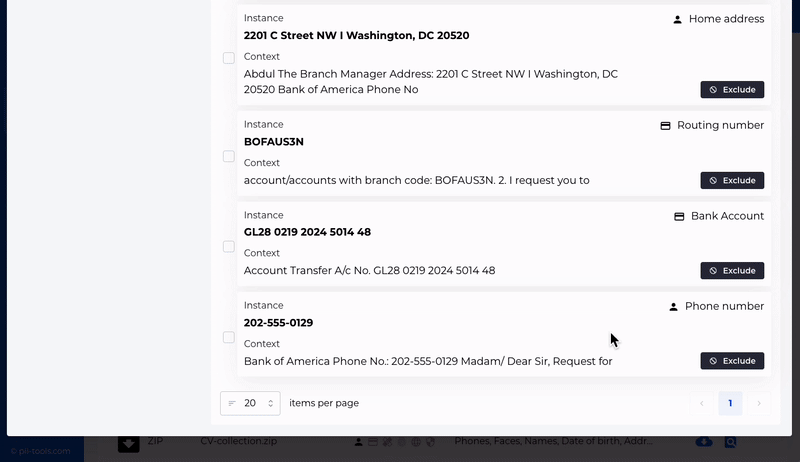
Remediate
Redact or erase unwanted personal information. Individually or in bulk.

Comply
Keep up with regulations with incremental and scheduled scans.
When to use PII Tools?
Audits & Compliance
Breach Investigations
Data Migrations
Consultants and MSPs

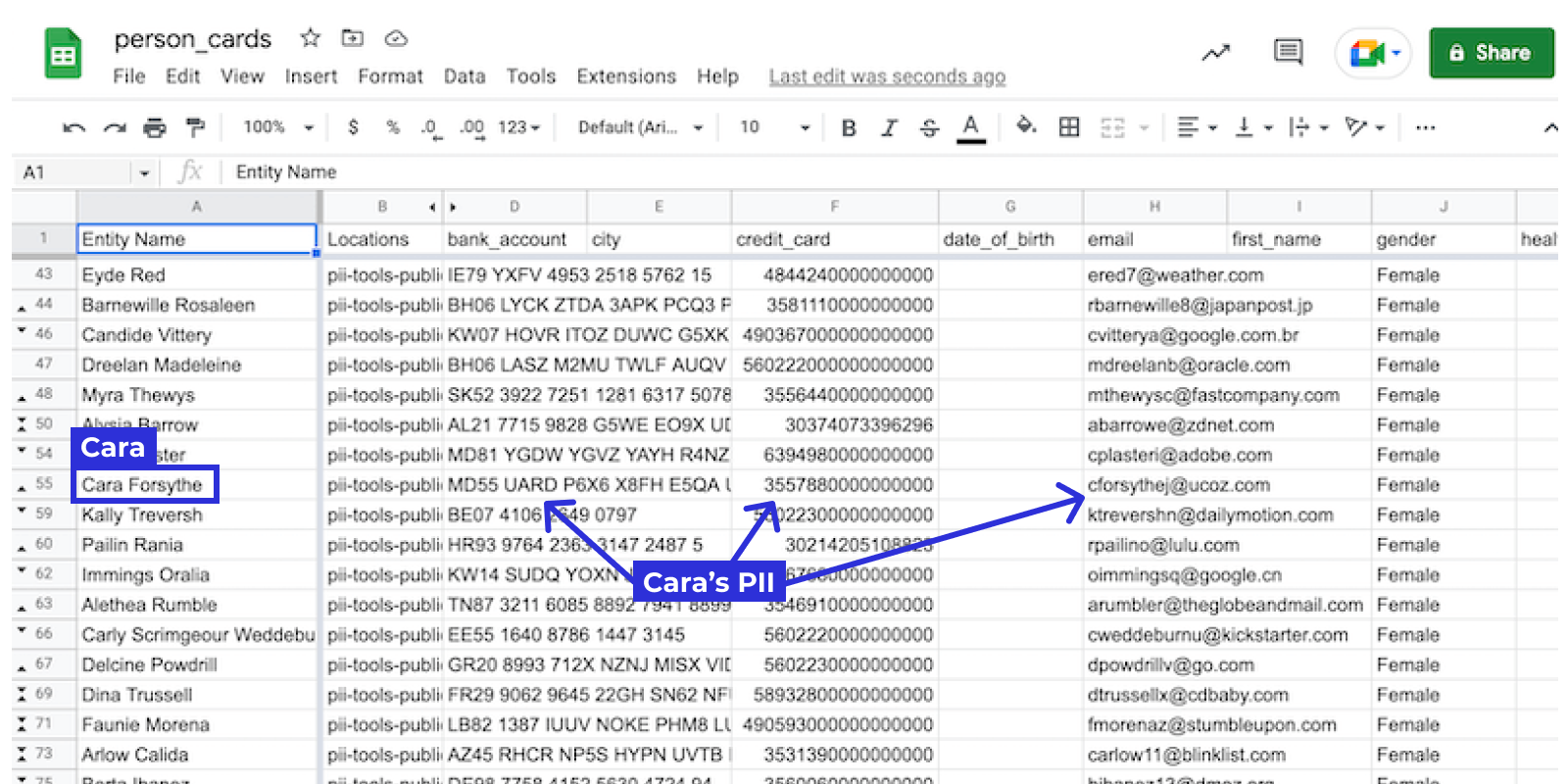
Person Cards
Document Redaction

Upload Protector
Detect PII data in 400+ file formats
PII Tools scans through all the sensitive data, local or cloud-based, structured and unstructured.
















Our customers say…



Mark Cassetta
SVP Strategy
“Our survey found that 22% of the time, humans failed to identify personal data in documents, while PII Tools succeeded in all scenarios. By integrating with PII Tools, Titus was able to significantly reduce the compliance risk for our customers.”

Raul Diaz
Senior Director, IT
“A manual data review would take us years and years, which was not an option. PII Tools provides us with a full report wherever there is any PII on our Sharepoint, GSuite, Microsoft Exchange, Salesforce, and physical devices.”
Want to know more about PII Tools?
Trusted by top brands worldwide
From purchase to your first scan in minutes

Instant Deployment
Install PII Tools on your own server in 30 minutes, using our PII Tools VMware or Docker image.

Scan & Analyze
Discover personal and sensitive data across your digital assets. In motion or at rest.

Take Action
Review, export, or remediate sensitive data from the Analytics dashboard.
